AWS Big Data Blog
Automating Analytic Workflows on AWS
| February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that AWS Data Pipeline service is in maintenance mode and we are not planning to expand the service to new regions. For information about migrating from AWS Data Pipeline, please refer to the AWS Data Pipeline migration documentation. |
Organizations are experiencing a proliferation of data. This data includes logs, sensor data, social media data, and transactional data, and resides in the cloud, on premises, or as high-volume, real-time data feeds. It is increasingly important to analyze this data: stakeholders want information that is timely, accurate, and reliable. This analysis ranges from simple batch processing to complex real-time event processing. Automating workflows can ensure that necessary activities take place when required to drive the analytic processes.
With Amazon Simple Workflow (Amazon SWF), AWS Data Pipeline, and, AWS Lambda, you can build analytic solutions that are automated, repeatable, scalable, and reliable. In this post, I show you how to use these services to migrate and scale an on-premises data analytics workload.
Workflow basics
A business process can be represented as a workflow. Applications often incorporate a workflow as steps that must take place in a predefined order, with opportunities to adjust the flow of information based on certain decisions or special cases.
The following is an example of an ETL workflow:

A workflow decouples steps within a complex application. In the workflow above, bubbles represent steps or activities, diamonds represent control decisions, and arrows show the control flow through the process. This post shows you how to use Amazon SWF, AWS Data Pipeline, and AWS Lambda to automate this workflow.
Overview
SWF, Data Pipeline, and Lambda are designed for highly reliable execution of tasks, which can be event-driven, on-demand, or scheduled. The following table highlights the key characteristics of each service.
| Feature | Amazon SWF | AWS Data Pipeline | AWS Lambda |
|---|---|---|---|
| Runs in response to | Anything |
Schedules |
Events from AWS services/direct invocation |
| Execution order | Orders execution of application steps |
Schedules data movement |
Reacts to event triggers / Direct calls |
| Scheduling | On-demand |
Periodic |
Event-driven / on-demand / periodic |
| Hosting environment | Anywhere |
AWS/on-premises |
AWS |
| Execution design | Exactly once |
Exactly once, configurable retry |
At least once |
| Programming language | Any |
JSON |
Let’s dive deeper into each of the services. If you are already familiar with the services, skip to the section below titled “Scenario: An ecommerce reporting ETL workflow.”
Amazon SWF
SWF allows you to build distributed applications in any programming language with components that are accessible from anywhere. It reduces infrastructure and administration overhead because you don’t need to run orchestration infrastructure. SWF provides durable, distributed-state management that enables resilient, truly distributed applications. Think of SWF as a fully-managed state tracker and task coordinator in the cloud.
SWF key concepts:
- Workflows are collections of actions.
- Domains are collections of related workflows.
- Actions are tasks or workflow steps.
- Activity workers implement actions.
- Deciders implement a workflow’s coordination logic.
SWF works as follows:
- A workflow starter kickoffs your workflow execution. For example, this could be a web server frontend.
- SWF receives the start workflow execution request and then schedules a decision task.
- The decider receives the task from SWF, reviews the history, and applies the coordination logic to determine the activity that needs to be performed.
- SWF receives the decision, schedules the activity task, and waits for the activity task to complete or time out.
- SWF assigns the activity to a worker that performs the task, and returns the results to Amazon SWF.
- SWF receives the results of the activity, adds them to the workflow history, and schedules a decision task.
- This process repeats itself for each activity in your workflow.
The graphic below is an overview of how SWF operates.

Source: Amazon Simple Workflow – Cloud-Based Workflow Management
To facilitate a workflow, SWF uses a decider to co-ordinate the various tasks by assigning them to workers. The tasks are the logical units of computing work, and workers are the functional components of the underlying application. Workers and deciders can be written in the programming language of your choice, and they can run in the cloud (such as on an Amazon EC2 instance), in your data center, or even on your desktop.
In addition, SWF supports Lambda functions as workers. This means that you can use SWF to manage the execution of Lambda functions in the context of a broader workflow. SWF provides the AWS Flow Framework, a programming framework that lets you build distributed SWF-based applications quickly and easily.
AWS Data Pipeline
Data Pipeline allows you to create automated, scheduled workflows to orchestrate data movement from multiple sources, both within AWS and on-premises. Data Pipeline can also run activities periodically: The minimum pipeline is actually just an activity. It is natively integrated with Amazon S3, Amazon DynamoDB, Amazon RDS, Amazon EMR, Amazon Redshift, and Amazon EC2 and can be easily connected to third-party and on-premises data sources. Data Pipeline’s inputs and outputs are specified as data nodes within a workflow.
Data Pipeline key concepts:
- A pipeline contains the definition of the dependent chain of data sources, destinations, and predefined or custom data processing activities required to execute your business logic.
- Activities:
- Arbitrary Linux applications – anything that you can run from the shell
- Copies between different data source combinations
- SQL queries
- User-defined Amazon EMR jobs
- A data node is a Data Pipeline–managed or user-managed resource.
- Resources provide compute for activities, such as an Amazon EC2 instance or an Amazon EMR cluster, that perform the work defined by a pipeline activity.
- Schedules drive orchestration execution.
- A parameterized template lets you provide values for specially marked parameters within the template so that you can launch a customized pipeline.
Data Pipeline works as follows:
- Define a task, business logic, and the schedule.
- Data Pipeline checks for any preconditions.
- After preconditions are satisfied, the service executes your business logic.
- When a pipeline completes, a message is sent to the Amazon SNS topic of your choice. Data Pipeline also provides failure handling, SNS notifications in case of error, and built-in retry logic.
Below is a high-level diagram.

AWS Lambda
Lambda is an event-driven, zero-administration compute service. It runs your code in response to events from other AWS services or direct invocation from any web or mobile app and automatically manages compute resources for you. It allows you to build applications that respond quickly to new information, and automatically hosts and scales them for you.
Lambda key concepts:
- Lambda function – You write a Lambda function, give it permission to access specific AWS resources, and then connect the function to your AWS or non-AWS resources.
- Event sources publish events that cause your Lambda function to be invoked. Event sources can be:
- AWS service, such as Amazon S3 and Amazon SNS.
- Other Amazon services, such as Amazon Echo.
- An event source you build, such as a mobile application.
- Other Lambda functions that you invoke from within Lambda
- Amazon API Gateway – over HTTPS
Lambda works as follows:
- Write a Lambda function.
- Upload your code to AWS Lambda.
- Specify requirements for the information execution environment, including memory requirements, a timeout period, an IAM role, and the function you want to invoke within your code.
- Associate your function with your event source.
- Lambda executes any functions that are associated with it, either asynchronously or synchronously depending on your event source.

Scenario: An ecommerce reporting ETL workflow
Here’s an example to illustrate the concepts that I have discussed so far. Transactional data from your company website is stored in an on-premises master database and replicated to a slave for reporting, ad hoc querying, and manual targeting through email campaigns. Your organization has become very successful, is experiencing significant growth, and needs to scale. Reporting is currently done using a read-only copy of the transactional database. Under these circumstances, this design does not scale well to meet the needs of high-volume business analytics.
The following diagram illustrates the current on-premises architecture.
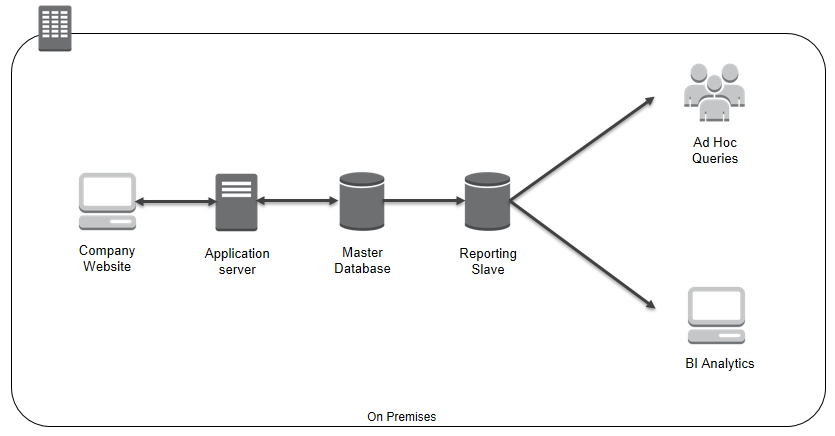
You decide to migrate the transactional reporting data to a data warehouse in the cloud to take advantage of Amazon Redshift, a scalable data warehouse optimized for query processing and analytics.
The reporting ETL workflow for this scenario is similar to the one I introduced earlier. In this example, I move data from the on-premises data store to Amazon Redshift and focus on the following activities:
- Incremental data extraction from an on-premises database
- Data validation and transformation
- Data loading into Amazon Redshift
I am going to decompose this workflow using AWS Data Pipeline, Amazon SWF, and AWS Lambda and highlight key aspects of each approach. I focus on three different approaches, with each approach focusing on an individual service. Please note that a solution using all three services together is possible, but not covered in this post.
AWS Data Pipeline reporting ETL workflow
Data Pipeline lets you define a dependent chain of data sources and destinations with an option to create data processing activities in a pipeline. You can schedule the tasks within the pipeline to perform various activities of data movement and processing. In addition to scheduling, you can also include failure and retry options in the data pipeline workflows.
The following diagram is an example of a Data Pipeline reporting ETL pipeline that moves data from the replicated slave database on-premises to Amazon Redshift:
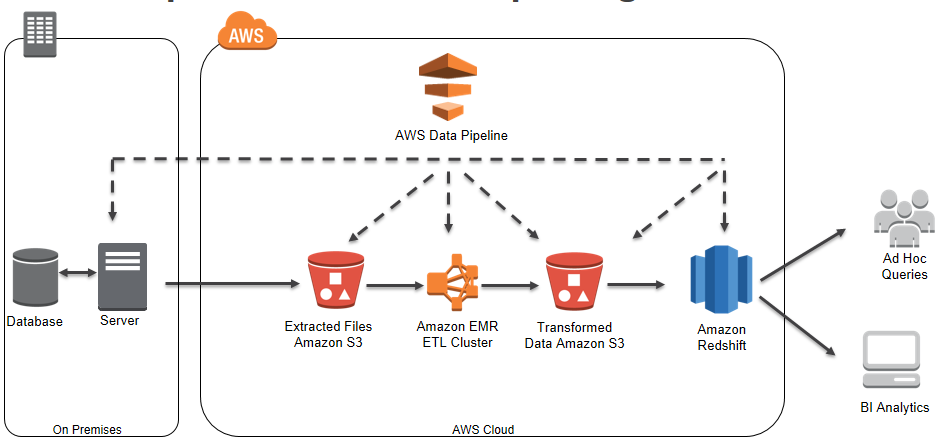
The above pipeline performs the following activities:
- ShellCommandActivity – Incrementally extracts data from an on-premises data store to Amazon S3 using a custom script hosted on an on-premises server with Task Runner installed.
- EmrActivity – Launches a transient cluster that uses the extracted dataset as input, validates, and transforms it, and then outputs to an Amazon S3 bucket as illustrated in the blog post on ETL Processing Using AWS Data Pipeline and Amazon Elastic MapReduce.
- CopyActivity – Performs an Amazon Redshift COPY command on the transformed data and loads it into an Amazon Redshift table for analytics and reporting.
Data Pipeline checks the data for readiness. It also allows you to schedule and orchestrate the data movement while providing you with failure handling, SNS notifications in case of error, and built-in retry logic. You can also specify preconditions as decision logic. For example, a precondition can check whether data is present in an S3 bucket before a pipeline copy activity attempts to load it into Amazon Redshift.
Data Pipeline is useful for creating and managing periodic, batch-processing, data-driven workflows. It optimizes the data processing experience, especially as it relates to data on AWS. For on-demand or real-time processing, Data Pipeline is not an ideal choice.
Amazon SWF on-demand reporting ETL workflow
You can use SWF as an alternative to Data Pipeline if you prioritize fine-grained, programmatic customization over the control flow and patterns of your workflow logic. SWF provides significant benefits, such as robust retry mechanisms upon failure, centralized application state tracking, and logical separation of application state and units of work.
The following diagram is an example SWF reporting ETL workflow.

The workflow’s decider controls the flow of execution from task to task. At a high level, the following activities take place in the above workflow:
- An admin application sends a request to start the reporting ETL workflow.
- The decider assigns the first task to on-premises data extraction workers to extract data from a transactional database.
- Upon completion, the decider assigns the next task to the EMR Starter to launch an EMR ETL cluster to validate and transform the extracted dataset.
- Upon completion, the decider assigns the last task to the Amazon Redshift Data Loader to load the transformed data into Amazon Redshift.
This workflow uses SWF for cron to automate failure handling and scaling in case you want to run your cron job on a pool of machines on-premises. In the latter case, this would eliminate any single point of failure, which is not possible with the traditional operating system cron.
Because the workers and deciders are both stateless, you can respond to increased traffic by simply adding more workers and deciders as needed. You can do this using the Auto Scaling service for applications that are running on EC2 instances in the AWS cloud.
To eliminate the need to manage infrastructure in your workflow, SWF now provides a Lambda task so that you can run Lambda functions in place of, or alongside, traditional SWF activities. SWF invokes Lambda functions directly, so you don’t need to implement a worker program to execute a Lambda function (as you must with traditional activities).
The following example reporting ETL workflow replaces traditional SWF activity workers with Lambda functions.
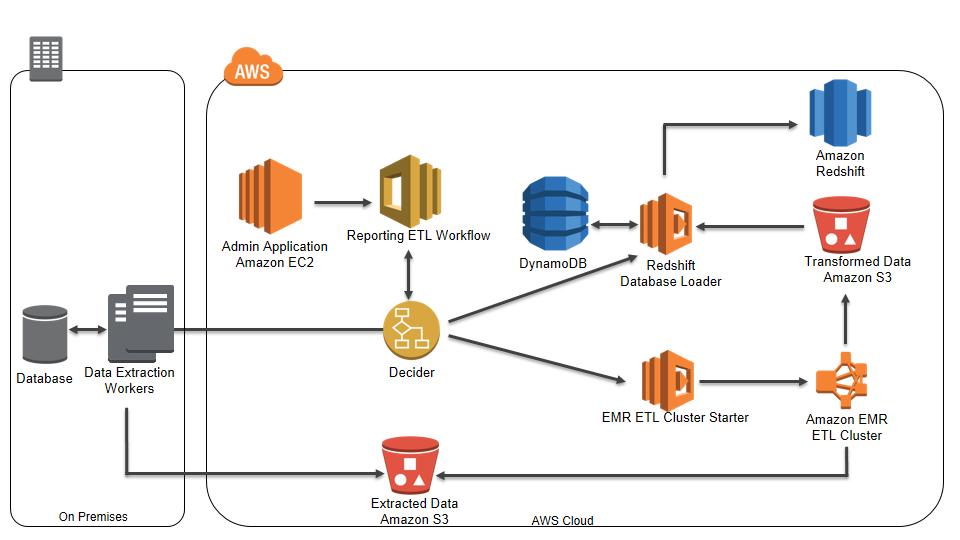
In the above workflow, SWF sequences Lambda functions to perform the same tasks described in the first example workflow. It uses the Lambda-based database loader to load data into Amazon Redshift. Implementing activities as Lambda tasks using SWF Flow Framework simplifies the workflow’s execution model because there are no servers to maintain.
SWF makes it easy to build and manage on-demand, scalable, distributed workflows. For event-driven reporting ETL, turn to Lambda.
AWS Lambda event-driven reporting ETL workflow
With Lambda, you can convert the reporting ETL pipeline from a traditional batch processing or on-demand workflow to a real-time, event processing workflow with zero administration. The following diagram is an example Lambda event-driven reporting ETL workflow.
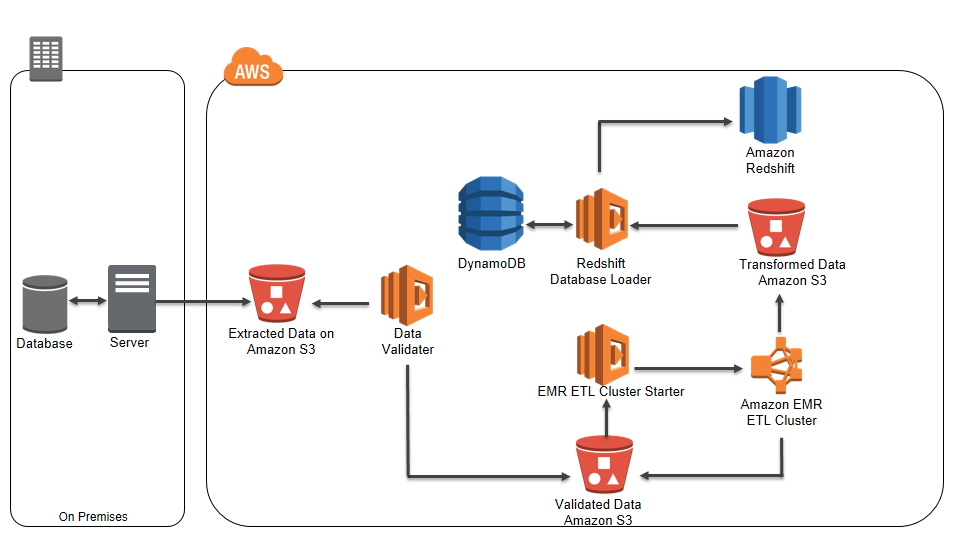
The above workflow uses Lambda to perform event-driven processing without managing any infrastructure.
At a high-level, the following activities take place:
- An on-premises application uploads data into an S3 bucket.
- S3 invokes a Lambda function to verify the data upon detecting an object-created event in that bucket.
- Verified data is staged in another S3 bucket. You can batch files in the staging bucket, then trigger a Lambda function to launch an EMR cluster to transform the batched input files.
- The Amazon Redshift Database Loader loads transformed data into the database.
In this workflow, Lambda functions perform specific activities in response to event triggers associated with AWS services. With no centralized control logic, workflow execution depends on the completion of an activity, type of event source, and more fine-grained programmatic flow logic within a Lambda function itself.
Summary
In this post, I have shown you how to migrate and scale an on-premises data analytics workload using AWS Data Pipeline, Amazon SWF, or AWS Lambda. Specifically, you’ve learned how Data Pipeline can drive a reporting ETL pipeline to incrementally refresh an Amazon Redshift database as a batch process; how to use SWF in a hybrid environment for on-demand distributed processing; and finally, how to use Lambda to provide event-driven processing with zero administration.
You can learn how customers are leveraging Lambda in unique ways to perform event-driven processing in the blog posts Building Scalable and Responsive Big Data Interfaces with AWS Lambda and How Expedia Implemented Near Real-time Analysis of Interdependent Datasets.
To get started quickly with Data Pipeline, you can use the built-in templates discussed in the blog post Using AWS Data Pipeline’s Parameterized Templates to Build Your Own Library of ETL Use-case Definitions.
To get started with SWF, you can launch a sample workflow in the AWS console, or try a sample in one of the programming languages, or use the SWF Flow programming Framework.
As noted earlier, you can choose to build a reporting ETL solution that uses all three services together to automate your analytic workflow. Data Pipeline, SWF, and Lambda provide you with capability that scales to meet your processing needs. You can easily integrate these services to provide an end-to-end solution. You can build upon these concepts to automate not only your analytics workflows, but also your business processes and different types of applications that can exist anywhere in a scalable and reliable fashion.
If you have questions or suggestions, please leave a comment below.
Related:
ETL Processing Using AWS Data Pipeline and Amazon Elastic MapReduce

About the author
Wangechi Doble is a Solutions Architect with AWS