AWS Big Data Blog
Snakes in the Stream – Feeding and Eating Amazon Kinesis Streams with Python
Markus Schmidberger is a Senior Consultant for AWS Professional Services
The Internet of Things (IoT) is becoming increasingly popular, and it’s easy to see why: it generates new business value for your company by connecting all available machines and devices. The big challenge is real-time data processing and analysis. Cloud computing is an excellent way to get started with IoT because it is flexible, scalable and elastic.
This blog post provides a simple tutorial for getting started with Amazon Kinesis, a fully managed, cloud-based service for real-time processing of distributed data streams, because you can integrate it in just about any IoT use case. For example, the News Distribution Network uses Amazon Kinesis to perform real-time analyses on their streaming data and creates alarms when the load performance is bad or when there are unusual user behaviors. To learn more, read News Distribution Network’s case study.
When data scientists develop concepts around how your company can use IoT, they often choose Python. Python is one of the top programming languages of choice in data science for prototyping, visualization, and running data analyses on any kind of data set. Boto is a python library that provides the AWS SDK for Python. Boto takes the complexity out of coding by providing Python APIs for many AWS services including Amazon Simple Storage Service (Amazon S3), Amazon Elastic Compute Cloud (Amazon EC2), Amazon Kinesis, and more. AWS provides an easy-to-read guide for getting started with Boto.
Amazon Kinesis Basics
The image below visualizes the key concepts and modules of Amazon Kinesis:
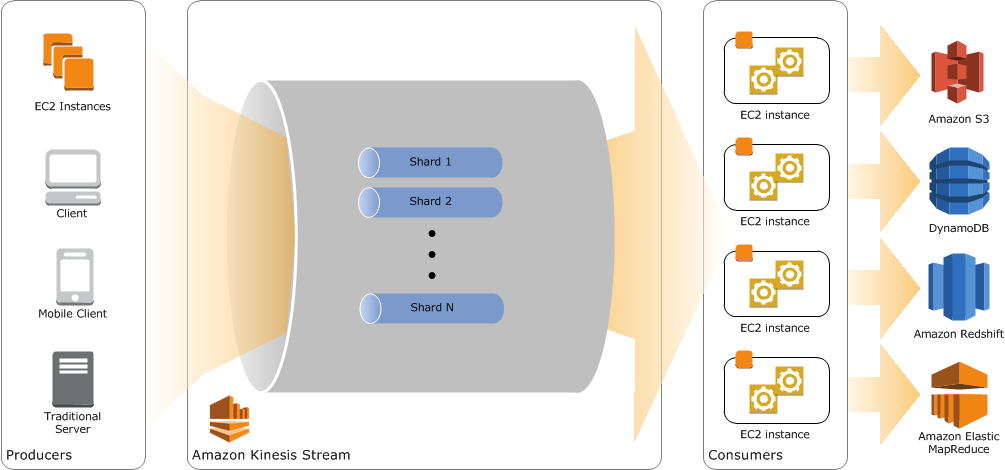
Producers generate data and enter this data as records into an Amazon Kinesis Stream, which is an ordered sequence of data records. A stream is composed of multiple shards, which is a uniquely identified group of data records. Consumers get these data records from the Amazon Kinesis Stream and process them. For example, a consumer can be a real-time dashboard or an application writing the data into another AWS service. To learn more about Amazon Kinesis read the Getting Started Webpage.
In the code examples I assume that you have a working Boto setup and your AWS credentials required for authorization are available. Boto provides a tutorial that helps you configure Boto.
Manage Amazon Kinesis and Create Data
The Boto library provides efficient and easy-to-use code for managing AWS resources. First, you start an Amazon Kinesis Stream in the eu-west-1 region with one shard and with the name BotoDemo. I also use the command describe_stream(‘BotoDemo’) to get more details about my stream and list_streams() to list all my existing streams which are in this case BotoDemo and IoTSensorDemo.
>>> from boto import kinesis
>>>
>>> kinesis = kinesis.connect_to_region("eu-west-1")
>>> stream = kinesis.create_stream("BotoDemo", 1)
>>> kinesis.describe_stream("BotoDemo")
{u'StreamDescription': {u'HasMoreShards': False, u'StreamStatus': u'CREATING', u'StreamName': u'BotoDemo', u'StreamARN': u'arn:aws:kinesis:eu-west-1:374311255271:stream/BotoDemo', u'Shards': []}}
>>> kinesis.list_streams()
{u'StreamNames': [u'BotoDemo', u'IoTSensorDemo'], u'HasMoreStreams': False}
For this tutorial, we will use simulated streaming data and implement the Python library “testdata” to generate personal data with first name, last name, age and gender. We choose this simple data structure to focus on and understand key Kinesis concepts. If you are interested in more challenging data, take a look at this Python package and connect your Amazon Kinesis Stream with Twitter.
>>> import testdata
>>> import json
>>>
>>> class Users(testdata.DictFactory):
... firstname = testdata.FakeDataFactory('firstName')
... lastname = testdata.FakeDataFactory('lastName')
... age = testdata.RandomInteger(10, 30)
... gender = testdata.RandomSelection(['female', 'male'])
Put Data into Amazon Kinesis
We now have a running Amazon Kinesis stream and are simulating streaming data with a simple for-loop in Python. The testdata package automatically creates JSON data, which you can directly send into Amazon Kinesis by adding one line of code for putting the data to Kinesis.
>>> for user in Users().generate(50):
... print(user)
... kinesis.put_record("BotoDemo", json.dumps(user), "partitionkey")
...
{u'ShardId': u'shardId-000000000000', u'SequenceNumber': u'49547280908463336004254488250210112303208011162475036674'}
{u'ShardId': u'shardId-000000000000', u'SequenceNumber': u'49547280908463336004254488250211321229027625791649742850'}
...
In the put_record() command, you must provide the stream name, the data blob to put into the record and a partition key which is used for sharding. In this case you only have one shard, so you don’t care about a good partition key. In the output from put_record() you can see that Amazon Kinesis creates a sequence number for every object you put into Amazon Kinesis and in which shard the object is stored.
Read Data from Amazon Kinesis
Now that you have data in your Amazon Kinesis Stream, the next step is to read data. We open an additional terminal window with an additional Python shell. With a simple endless while-loop, I am reading the latest records from my stream.
>>> from boto import kinesis
>>> import time
>>>
>>> kinesis = kinesis.connect_to_region("eu-west-1")
>>> shard_id = 'shardId-000000000000' #we only have one shard!
>>> shard_it = kinesis.get_shard_iterator("BotoDemo", shard_id, "LATEST")["ShardIterator"]
>>> while 1==1:
... out = kinesis.get_records(shard_it, limit=2)
... shard_it = out["NextShardIterator"]
... print out;
... time.sleep(0.2)
...
{u'Records': [{u'PartitionKey': u'partitionkey', u'Data': u'{"lastname": "Rau", "age": 23, "firstname": "Peyton", "gender": "male"}', u'SequenceNumber': u'49547280908463336004254488250517179461390244620594577410'}, {u'PartitionKey': u'partitionkey', u'Data': u'{"lastname": "Mante", "age": 29, "firstname": "Betsy", "gender": "male"}', u'SequenceNumber': u'49547280908463336004254488250518388387209859249769283586'}], u'NextShardIterator': u'AAAAAAAAAAEvI7MPAuwLucWMwYtZnATetztUUTqgtQaTaihyV/+buCmSqBdKnAwv2dMNeGlYo3fvYCcH6aI/A+DtG3uq+MnG8AlyrX7UrHnlX5OF0xG/IEhSJyyToPvwtJ8odDoWShib3bjuk+944QcsPrRRsUsBNx6xyKgnY+xi9lXvweiImL1ByK5Bdj0sLoRp/9nBWfw='}
First, we must create a shard iterator that specifies the position in the shard from which to start reading data records sequentially. In this case (“LATEST”) we are reading the most recent records in the shard. AWS provides a reference guide that helps you specify the different available shard iterator types. The get_records() command gets a batch of records. For demonstration, we are limiting the number of get records to two. Furthermore, each shard can support up to five read transactions per second. Therefore, we use the sleep() command to control the number of reads per second. Amazon Kinesis documentation provides more information about service limits. Each output of the latest get_records() command additionally provides the next shard iterator for your next get_records operation.
Now you can analyze the latest data in Amazon Kinesis and visualize this data in a dashboard. The following code calculates the average age of the simulated data in Amazon Kinesis.
>>> from boto import kinesis
>>> from boto import kinesis
>>> from __future__ import division
>>> import time
>>>
>>> kinesis = kinesis.connect_to_region("eu-west-1")
>>> shard_id = 'shardId-000000000000' #we only have one shard!
>>> shard_it = kinesis.get_shard_iterator("BotoDemo", shard_id, "LATEST")["ShardIterator"]
>>> i=0
>>> sum=0
>>> while 1==1:
... out = kinesis.get_records(shard_it, limit=2)
... for o in out["Records"]:
... jdat = json.loads(o["Data"])
... sum = sum + jdat["age"]
... i = i+1
... shard_it = out["NextShardIterator"]
... if i <> 0:
... print "Average age:" + str(sum/i)
... time.sleep(0.2)
...
Re-Shard the Amazon Kinesis Stream
Elasticity and scaling are core features of Amazon Web Services. So far, the described use-case does not scale efficiently. An Amazon Kinesis shard is limited by the number of read and write operations per second and capacity. To scale your application, you can add and remove shards at any time. So let’s split the current shard into two shards and use a more efficient partition key to write into Amazon Kinesis.
>>> sinfo = kinesis.describe_stream("BotoDemo")
>>> hkey = int(sinfo["StreamDescription"]["Shards"][0]["HashKeyRange"]["EndingHashKey"])
>>> shard_id = 'shardId-000000000000' #we only have one shard!
>>> kinesis.split_shard("BotoDemo", shard_id, str((hkey+0)/2))
>>>
>>> for user in Users().generate(50):
... print user
... kinesis.put_record("BotoDemo", json.dumps(user), str(hash(user["gender"])))
...
{'lastname': 'Hilpert', 'age': 16, 'firstname': 'Mariah', 'gender': 'female'}
{u'ShardId': u'shardId-000000000001', u'SequenceNumber': u'49547282457763007181772469762801693095350958144429752338'}
{'lastname': 'Beer', 'age': 13, 'firstname': 'Ruthe', 'gender': 'male'}
{u'ShardId': u'shardId-000000000002', u'SequenceNumber': u'49547282457785307926971000385136875291940648846406713378'}
{'lastname': 'Boehm', 'age': 30, 'firstname': 'Lysanne', 'gender': 'female'}
{u'ShardId': u'shardId-000000000001', u'SequenceNumber': u'49547282457763007181772469762802902021170572773604458514'}
{'lastname': 'Bechtelar', 'age': 17, 'firstname': 'Darrick', 'gender': 'male'}
{u'ShardId': u'shardId-000000000002', u'SequenceNumber': u'49547282457785307926971000385138084217760263475581419554'}
...
To split a shard, we must specify the shard that is to be split and the new hash key, which is the position in the shard where the shard gets split. In many cases, the new hash key might simply be the average of the beginning and ending hash key, but it can be any hash key value in the range being mapped into the shard.
Now we have to provide a more efficient partition key for the put_record() command. Amazon Kinesis is using a MD5 hash function to map partition keys to 128-bit integer values and to map associated data records to shards using the hash key ranges of the shards. It is a best practice to use a partition key with a higher number of groups than shards. In this case the gender field is a good partition key for demonstration. In the output of put_record() you can see that male and female data objects are put into different shards. The scaling of this approach will be limited to two shards again. A scalable partition key for this data example would be the age value.
In addition to scaling out, you should always think about scaling in. Check the merge_shards() command to combine two shards in case of a low load.
Optimized Put Operations
So far, we have put each record separately into Amazon Kinesis. As soon as you have more producers and the amount of data is growing, this will create a high latency for writing into Amazon Kinesis. When that happens, consider combining objects to batches and write bigger groups of objects into your Amazon Kinesis stream.
>>> i=0;
>>> records=[];
>>> for user in Users().generate(50):
... i=i+1
... record = {'Data': json.dumps(user),'PartitionKey': str(hash(user["age"]))}
... records.append(record)
... if i%5==0:
... kinesis.put_records(records, "BotoDemo")
... records=[];
The put_records() command is available in Boto version v2.36.0 and higher (released 27-Jan-2015). For this batch operation, you combine several records (in this case 5) to an array. Each element is an object with a Data field and a PartitionKey field. After collecting five elements in the array, we send this data to Amazon Kinesis and start creating a new array.
When you have finished with this tutorial, delete your Amazon Kinesis stream.
>>> kinesis.delete_stream("BotoDemo")
Conclusion
Amazon Kinesis is a powerful AWS service for managing stream data. It is very useful for storing and analyzing data from machine logs, industry sensors, website clickstreams, financial transactions, social media feeds, IT logs, location-tracking events and much more. Amazon Kinesis is a perfect fit with the emerging Internet of Things.
The Python library Boto provides a great interface for data scientists to work with Amazon Kinesis and other AWS services. You can manage your stream and can put into and read data from Amazon Kinesis with Python in fewer than 10 lines of code. If you prefer to use a lower-level programming language, check the AWS Java SDK which provides an excellent Amazon Kinesis integration tool.
If you have questions, comments, or suggestions, please start a thread in the Amazon Kinesis forum or enter a comment below.
Do more with Amazon Kinesis:
Processing Amazon Kinesis Stream Data Using Amazon KCL for Node.js
Hosting Amazon Kinesis Applications on AWS Elastic Beanstalk
